

Moving from floating-point representation to quantization involves converting the continuous range of floating-point numbers to a discrete set of values represented by integers. This process is important for optimizing machine learning models, particularly for deployment in edge computing. Quantization aims to reduce the memory footprint, computational complexity, and energy consumption of models by representing weights and activations using fewer bits.
In a typical neural network, the hardware implementation determines quantization.
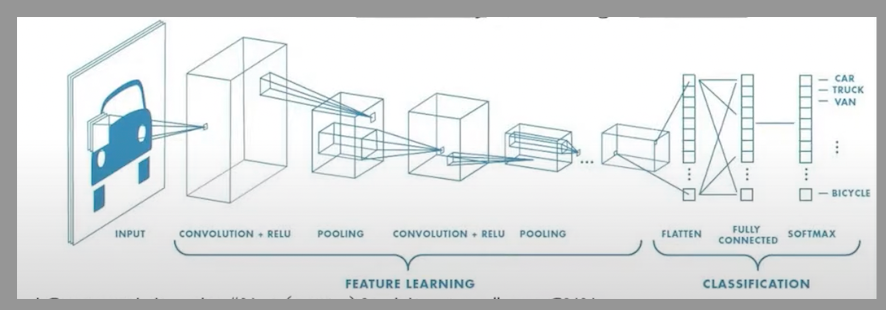
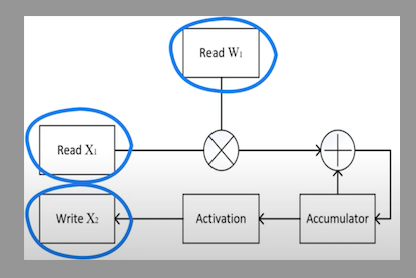
Most of the hardware multiply and accumulation unit happens in one clock cycle inside a MAC (Multiply and Accumulate Unit) unit.

A typical filter in Neural Network (3,3,256), ~2.5k (3x3x256) MAC operations. The energy consumption as per chart below:
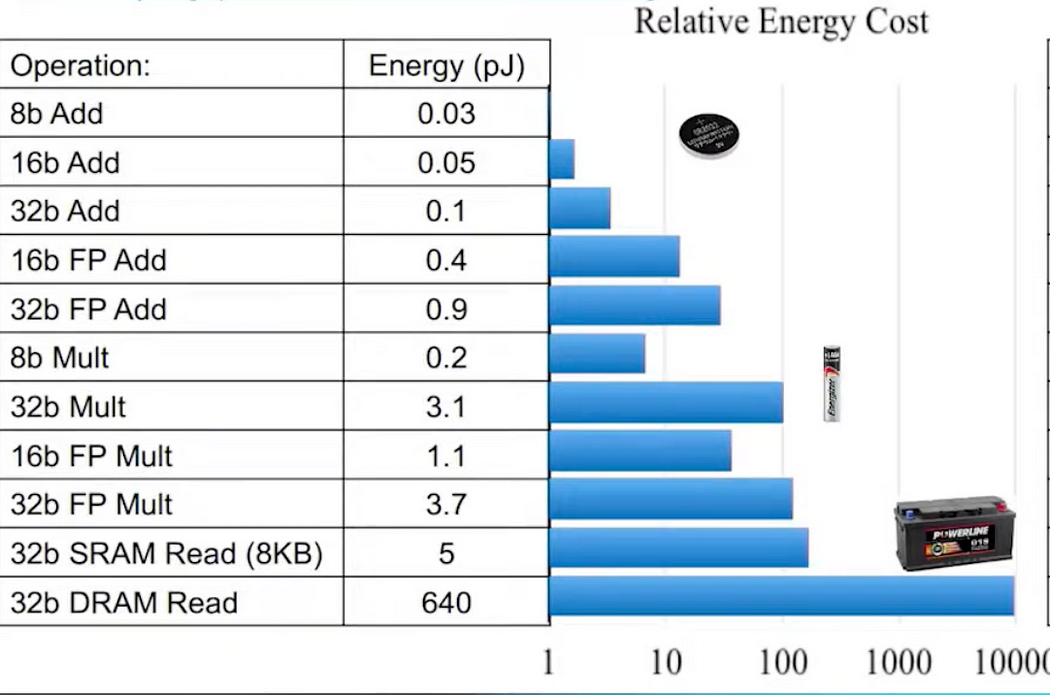
From the image above, it’s evident, more the number of bits higher the power consumption. 32 bit multiplication operation requires about 3.1 pJ, whereas 8bit multiplication requires .2 pJ or in other words 16x less power consumption. Another thing to notice is the local reads are cheap and external reads are expensive. Most of the power consumption is happening when the memory is accessed for reading or writing. If it’s external memory, the read/write is very expensive. So the idea is if the data is kept local somehow, there will be lots of enegy savings.
Why is Quantization Beneficial?
As we noticed, the external memory access is expensive and compute is cheap for lower bits in terms of power. Hence, the acceptable design principal is how to maximize compute per external memory access, this explains why quantization is important. So, in modern DL accelerators for DL inference, the quantization is done before accessing the memory. So instead of reading 32bit from memory, read 8bit from memory dequantize them before doing 32bit MAC operation. So from the diagram below, there will be 4 times the memory bandwidth reduction and 1 compute.

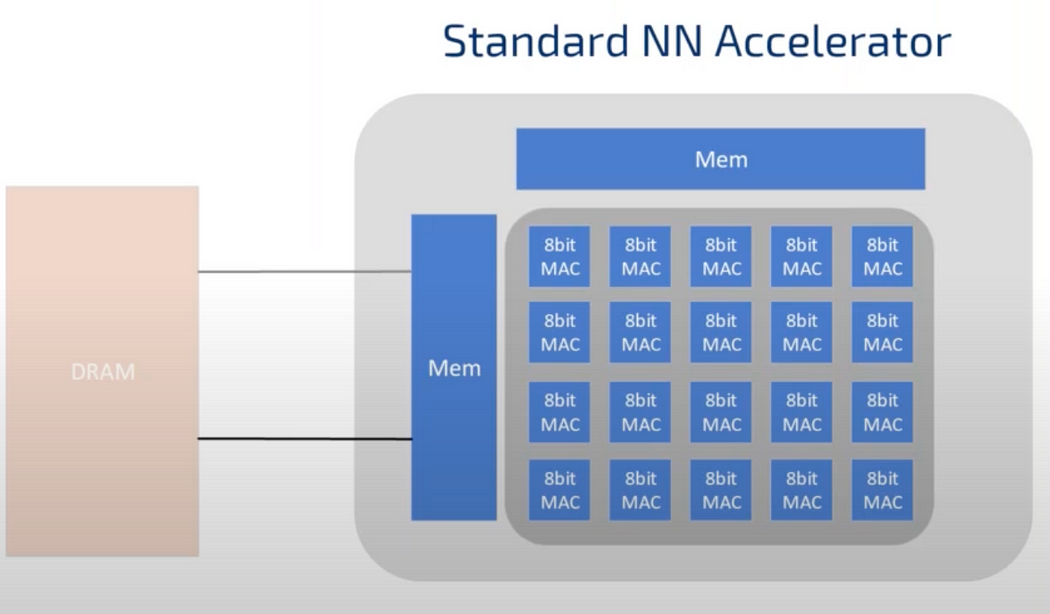
Still better, instead of dequantising, if hardware supports 8 bit MAC, it can handle 4 8bit operations. This maximizes compute per external memory access, i.e, 4 times the memory bandwidth reduction so less power consumption and 4 times the compute.
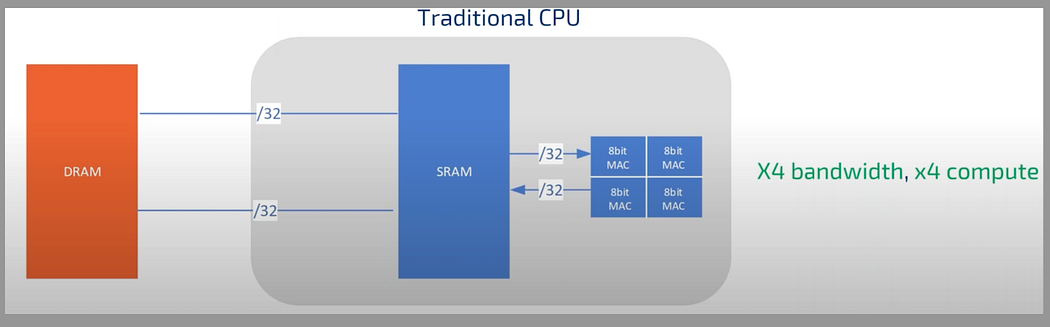
Modern computer’s implementation of NN accelerators take advantage of large number of small sized 8bits MAC to create large compute density. They make use of metrix like structure to make use of the weights in several computations.
to be concluded..
